Lesson 8
Building embeddings from scratch
- What will part 2 feel like? a lot deeper technically? Able to read and implement research papers? Models involve real life situations?
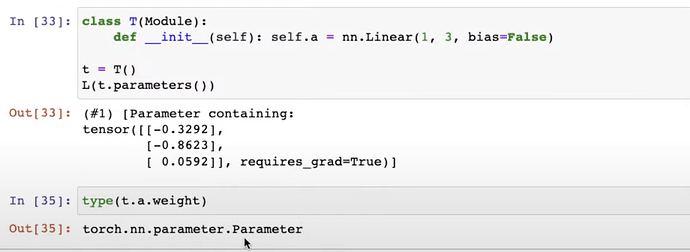
- Review build a neuralnet from scratch. How Pytorch create a neuralnet effortlessly? How Pytorch keep track of model weights through
Module? How doesModulestore weights withnn.Parameter? How to check weights from the model usingparameters()?

- You can build a layer in Module with
nn.Linearwithoutnn.Parameterand Pytorch can read weights from it too.
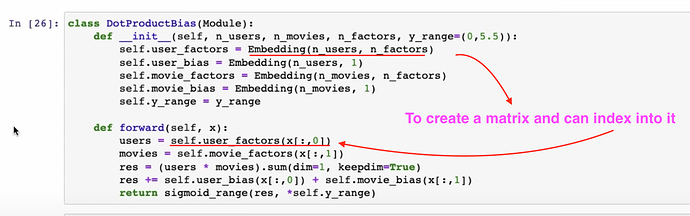
- How to create the
Embeddingfunction and the entireDotProductBiaswith pytorch usingcreate_paramsfrom scratch? After it’s trained, the trainedmovie_biascan be checked. You can check the shape of the bias bymodel.movie_bias.shape
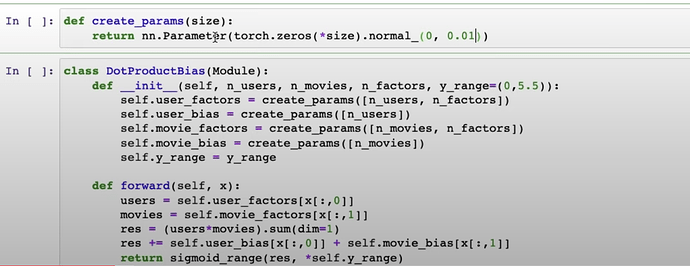
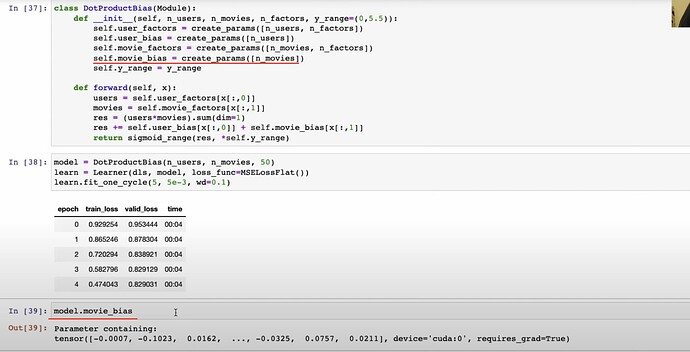
- Questions: What does
Tensor.normal_do?


Interpretation of embeddings
- After training, what can the
movie_biastell us about each and all the movies? What does having a low bias mean for a movie? What does having a high bias mean for a movie? Canuser_biastell us which user just loves movies even the crapy ones? This is visualizingmovie_bias

- What can we interpret or do about the huge matrix with shape
(num_users, 50)? How to shrink the 50 latent factors into just 3 most important factors withpca?
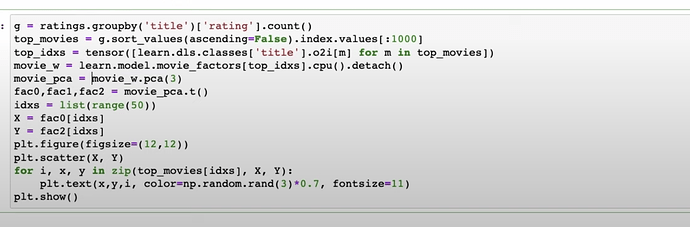
- How to interpret the PCA chart of movies rated with only just two PCA factors of out 3 compressed by 50 factors? How the taste or style of the movies are condensed into two factors and displayed and defined by the location of the two dimensional chart? This is visualizing movie_factors or embeddings.

- How fastai makes all the work above easier with just one line of code?
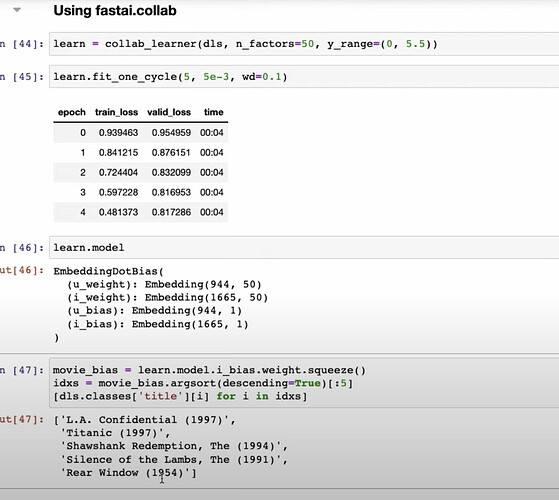
- How fastai construct everything under the hood of
collab_learner?
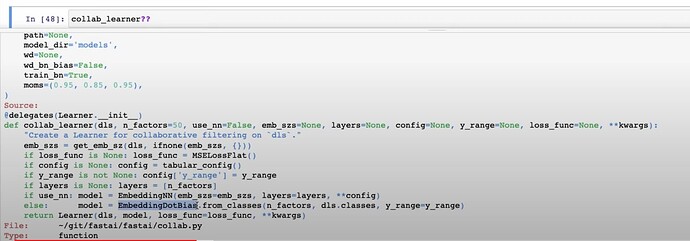
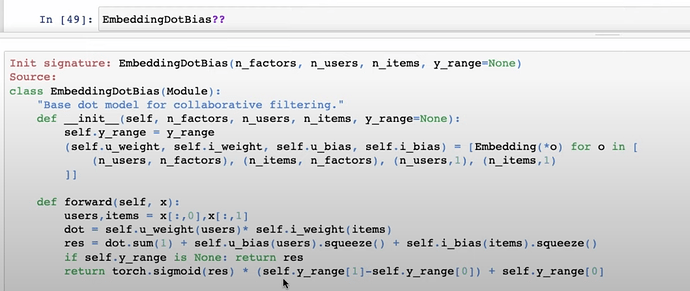
- Questions: is PCA useful in other applications? Where to find more of PCA? Why should you take Rachel’s Computational Linear Algebra?
- How to use Embedding distance to find out movie similarities?
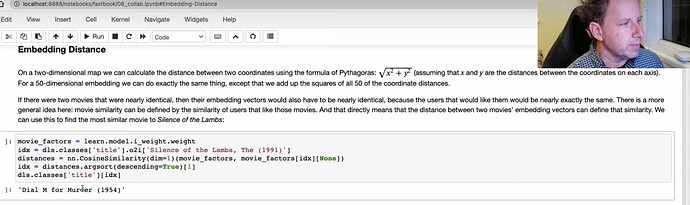
- Go to read the fastbook for boostrapping a collaborative filtering model
Deep learning for collaborative filtering
- How to do collaborative filtering with deep learning instead of matrix completion with dot product above? How to apply the easist neuralnet model architecture onto this collaborative filtering case?
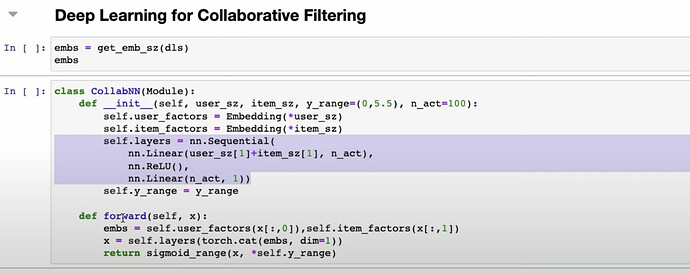
- How does fastai use rules of thumb to recommend the number of latent factors for users and movies?

- How does fastai use deep learning to build collaborative filtering model in two ways?
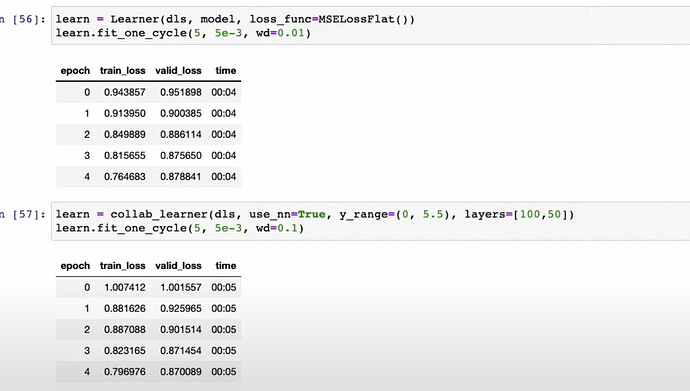
Why the deep learning versions are not as good as DotProduct version? Is it because DotProduct is more tailored to the problem? How do companies combine both versions to do collaborative filtering? When you have lots of metadata, should you apply deep learning to it? How would you use metadata in the model? - Questions: Can a smaller number of users and movies overwhelm everybody else? e.g., a small group of anime enthusiasts watch a lot of anime movies and give super high ratings. Details of how to deal with them won’t be discussed here - How to apply embedding matrix into NLP model through a spreadsheet demo? What’s the essense of neuralnet?
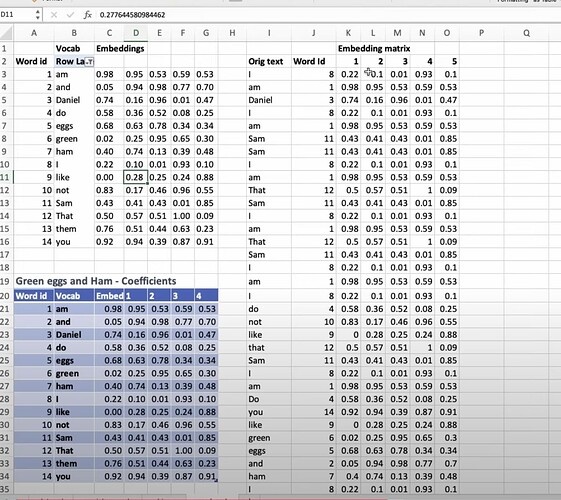
- How to apply embeddings to tabular dataset and models? How to understand
TabularModelandtabular_learnersource? - What’s going on inside a neuralnet through a shop sale prediction kaggle competition and a paper published based on it?
Convolutions
- So far we have looked at what goes in as inputs and what goes out of a model as outputs. We have also looked at the middle as matrix multiplication. What are convolution (a particular kind of matrix multiplication in the middel)? How is it be very useful to CV? Why MNIST is one of the most famous CV dataset? How does Jeremy apply what Fergus and Zeiler’s paper onto MNIST using excel and convolution?
- How to understand convolution? What does a filter do and How does it help to detect horizontal and vertical edges? How to determine the size of the filter or kernel (3x3, or 5x5, or any)? conv1 means the first convolutional layer
- moving onto the second convolutional layer. Two filters give us two channels on the first convolutional layer. On the second convolutional layer, we create one 3D matrix filter which has two matrix filters to filter/process the two channels out of the first conv layer, and condense the value. And we can also create a second channle for the 2nd conv layer using another 3D filter.
- How to determine the output and use SGD to train the model and optimize the filters?
- What is maxpooling? What’s the problem of maxpooling? How much data do we lose? Why it is a good thing? What is a dense layer and what does it do?
- How we do convolution slightly differently today? What is stride-two convolution and how does it work? (no more maxpooling) Then we do a lot of stride-two convolutions until the size shrinked to 7x7 and then do a
average_pooling(no more dense layer). What does the 7x7 grid and take an average mean? What is the problem of such approach? When is the good time to use maxpool instead? How fastai made it easy for us to try both pooling by inventing a technique calledconcat_poolingto maxpool andaverage_pooland concat them together? - How to understand convolution in terms of matrix multiplications?
- What is dropout and how to understand it using excel? What is droput mask? What’s its effect visually on excel? How to understand dropout as data augmentation for the activations? How does it help avoid overfitting? What’s the story of dropout and academia?
- Why Jeremy not spend much time on activation functions? We have seen many functions on metrics, loss and activations.
- What to do next before fastai part2? What Radek’s book meta learning is about? What are the things to do in Write, Help, Gather and Build?
- a fastai community member published mish activation used by many state of art models.
Jeremy AMA
- How to keep up? To keep up by focusing in subfield of deep learning and focusing on things that don’t change much as the foundations of fastai have not changed much from 5 years ago. Everything else is just tweaks.
- Will huge dataset and GPU computation replace us with small dataset and one gpu? There is always smarter ways of doing things, eg. Fastai team trained on imagenet on standard GPU faster than all companies with huge amount of GPUs. Pick areas of different domains which smaller models can beat the state of the art.
- How Jeremy to teach kids math? all kids can learn algebra with dragonbox5+. Great, Jeremy promised to talk more about teaching kids some point later.
- Plans for walkthrus
- How to turn a model into business? Great news, Jeremy plans to build a course on this! What is the start of a business? What is the first step? How to gradually figure out whether your idea has a real need from people?
- How Jeremy stay so efficient at working? Finish something nicely, tenacity